

-
Open your PDF: Launch the PREP application and open the document you wish to inspect.
-
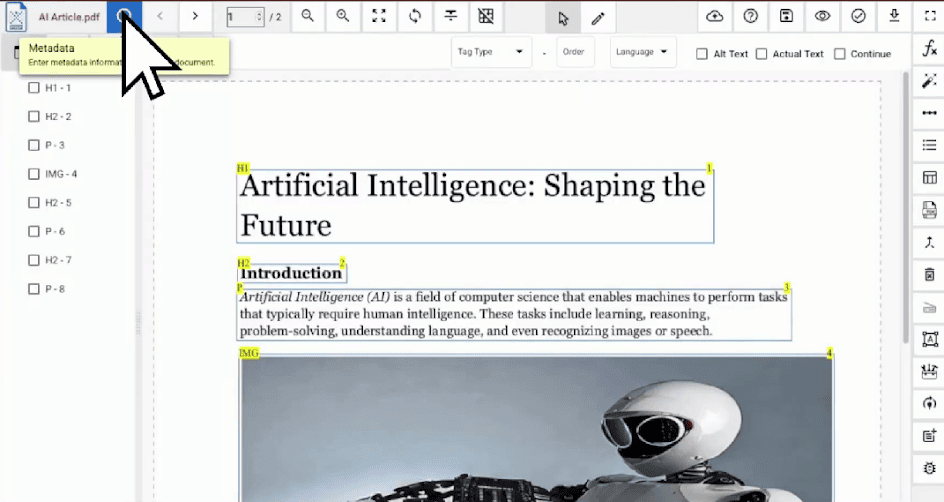
Locate the Metadata Icon: On the top toolbar, click the Metadata icon (represented by a small "i" inside a circle).
-
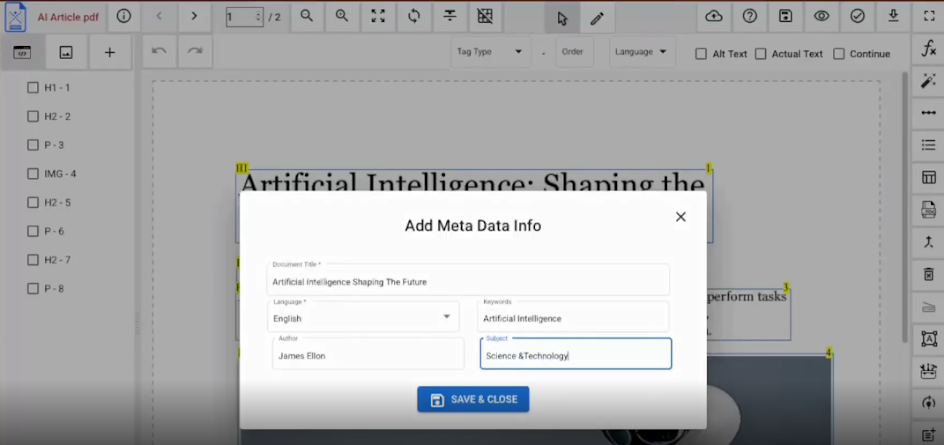
View the Details: A pop-up window titled "Add Meta Data Info" will appear, displaying the current Title, Language, Keywords, and Subject of the file.
-
Open Your File
- Launch the PREP application on your device.
- Go to File > Open or simply drag and drop your PDF file into the PREP window.
-
Locate the Metadata Tool
- Look at the top toolbar.
- Click on the Metadata icon, usually shown as a tag or info symbol.
-
Fill in Metadata Fields
Once the Metadata Panel or pop-up opens, you will see several fields to complete. Enter your details in each of these:
- Title: Type the full name of your document (e.g., "Annual Budget Report 2026").
- Language: Select the main language used in the document (e.g., English, Hindi).
- Keywords: Add words or phrases related to the document, separated by commas. These help others find your PDF using search (e.g., "financial report, budget, 2026").
- Author: Enter the name of the person, department, or organization responsible for the document.
- Subject: Write a short one-line summary of the document's purpose or contents.
-
Save and Apply Metadata
- After reviewing all entries for accuracy, click the Save button at the bottom of the metadata panel.
- This will embed the metadata directly into the PDF file.
-
Load the PDF in PREP
- Open PREP and drag your file in or use File > Open to load the PDF.
-
Open the Metadata Panel
- Click the Metadata icon on the top toolbar to see the current embedded metadata.
-
Manually Clear Each Field
- Click inside each of the fields like Title, Author, Subject, etc.
- Highlight the existing text and press Backspace or Delete on your keyboard.
- Make sure all the fields you want to clear are completely empty. You can choose to leave some fields filled if needed.
-
Save the Clean File
- Once you have cleared all necessary fields, click Save.
- PREP will overwrite the existing metadata with the now-empty values, removing all the hidden information from the file.
-
Missing or Incomplete Title
What's the Problem?
The document shows "Untitled" or just a random filename like final_draft3.pdf in the browser tab or screen reader.
Why it Matters:
This creates confusion for users and affects SEO. Assistive technologies cannot correctly identify the document.
How to Fix in PREP:
-
Open the PDF in PREP.
-
Click the Metadata Icon in the top toolbar (usually marked with an "i" or a tag symbol).
-
In the Title field, enter a descriptive document name like 2026 Annual Report.
-
Click Save to apply the change.
-
-
Incorrect Author Information
What's the Problem?
The Author metadata shows names like "Admin," "Scanner," or past employees.
Why it Matters:
It lowers the credibility of the document and misrepresents authorship.
General Fix:
- Audit the Author field manually using your PDF editor.
- Use a consistent naming format, such as "Communications Team" or "Legal Department."
How to Fix in PREP:
-
Open your file and go to the Metadata Panel.
- Clear out the old name in the Author field.
-
Type in the correct name or department.

-
Hit Save.
-
Blank or Misleading Subject and Keywords
What's the problem?
Subject and Keywords fields are either left blank or filled with unrelated terms.
Why it Matters:
Search engines and internal systems cannot sort or classify the document properly.
General Fix:
- In the Subject field, write a short summary of the document's content.
- In the Keywords field, use relevant tags separated by commas.
How to Fix in PREP:
-
Open the PDF in PREP and go to the Metadata Tool.
- Fill in the Subject with a phrase like Budget analysis for Q2.
-
Add Keywords such as: Budget, Q2, Analysis, Financial.
-
Save the changes.
-
Incorrect Language Setting
What's the Problem?
The document's language metadata is missing or set to the wrong language.
Why it Matters:
Screen readers use the wrong pronunciation, making the document unusable for visually impaired users.
How to Fix in PREP:
-
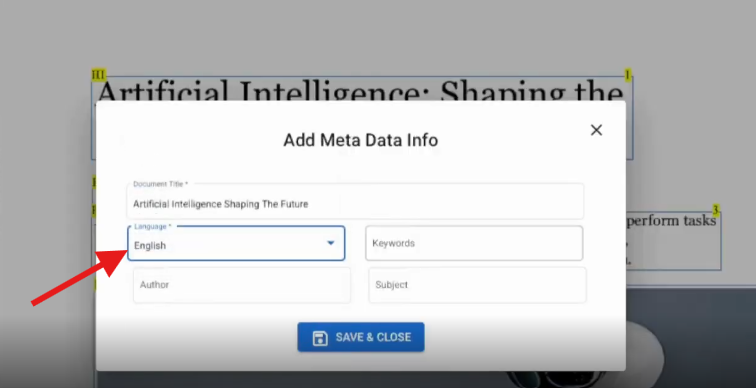
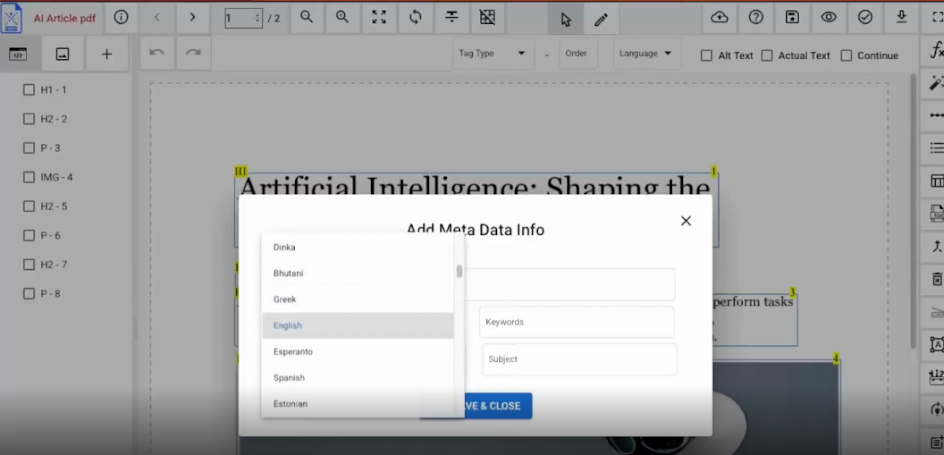
Open the PDF and click the Metadata Icon.
- Find the Language dropdown.
-
Select the correct option, like English - US.
-
Save to apply.
-
-
Conflicts Between Document Info and XMP Metadata
What's the Problem?
The document's Info and XMP panels show different data, like two different titles or authors.
Why it Matters:
This causes confusion during search and can trigger compliance errors in some systems.
How to Fix:
- Open the Advanced Metadata Panel.
- Compare fields and make sure both sets (Info and XMP) match.
- Use a single master template to avoid inconsistency in future exports.
-
Outdated or Incorrect Creation/Modification Dates
What's the Problem?
Dates show as several years old or are clearly inaccurate due to copying files from old systems.
Why it Matters:
It creates confusion in version control and affects document reliability.
How to Fix:
- Use the Document Properties panel to edit timestamps if allowed.
- If not editable, regenerate the file using updated software.
- Set clear date rules for your team when exporting or saving PDFs.
-
Missing Accessibility Metadata
What's the Problem?
Fields like document language, tagged status, or alt-text indicators are not set.
Why it Matters:
The PDF fails accessibility standards like WCAG or PDF/UA, making it hard for assistive tech to read.
How to Fix:
- Tag the document properly using tools like PREP or Adobe Acrobat.
- Make sure all images have alt text.
- Run an accessibility checker to validate your document.
-
Deprecated or Non-Standard Metadata Fields
What's the Problem?
Old or custom metadata fields from legacy tools are still embedded in the file.
Why it Matters:
These fields cause issues when sharing files across platforms or uploading to CMS systems.
How to Fix:
- Remove deprecated tags using your metadata editor.
- Replace them with standard, recognised XMP fields.
- Validate the structure using schema validation tools.
-
Confidential or Excessive Metadata
What's the Problem?
PDF metadata contains sensitive information like usernames, device names, or internal project notes.
Why it Matters:
This can lead to privacy leaks, especially when the document is shared externally.
How to Fix:
- Always scrub metadata before sharing.
- Use tools like PREP or Acrobat to strip hidden metadata.
- Set up a routine that automatically removes sensitive data during publishing.
-
Metadata Not Embedded Properly or Completely Missing
What's the Problem?
The file might have the right filename, but the metadata fields inside the PDF are empty or missing entirely.
Why it Matters:
Search tools, assistive readers, and archiving systems cannot access or identify the file correctly.
How to Fix:
- Open the Document Properties or XMP panel and enter all required metadata manually.
- If exporting in bulk, ensure your system embeds metadata properly during export.
- Use a preflight checker to confirm that the data is embedded and usable.



